
Mock AI
Overview

MockAI is an AI-powered platform designed to help job seekers, initially focusing on software engineers, master their technical and behavioral interviews. The product provides a realistic, on-demand practice environment where users can interact with an intelligent AI interviewer, receive instant, data-driven feedback, and track their improvement over time.
As the founding Product Manager, I owned the product strategy and execution from its earliest stages. I scaled the platform from a 50-user closed-alpha to a publicly launched product serving over 7k users.
This case study details how a user-first approach, a lean MVP strategy, and a focus on product-led growth turned a critical user problem into a rapidly scaling solution.
Customer Challenges
From our survey of 200+ tech recruiters, 96% prioritize candidates with stronger communication skills. 2 millions+ engineers and students prep for coding interviews on paper but lack an affordable way to practice speaking out loud. The job interview process, especially in tech, is a high-stakes, high-stress experience. Through dozens of initial user discovery interviews, we identified three core, unaddressed challenges for job seekers:
Lack of Low-Cost Realistic Practice: Candidates struggle to find opportunities for realistic practice. Mock interviews with experienced professionals are very expensive, usually ranging $150-300 per session, especially for students. Mock interviews with friends are helpful but not always available, and practicing alone lacks the pressure and interaction of a real interview.
Absence of Objective Feedback: It's incredibly difficult to get honest, objective, and expert-level feedback. Candidates often leave real interviews with no idea how they performed or what specific areas they need to improve upon.
The "Silent Coder" Problem: Most critically, we discovered that even when candidates practice on platforms like LeetCode, they are inadvertently training the wrong habit: solving problems in silence. A real technical interview is a test of communication and collaboration. Candidates struggle to articulate their thought process, ask clarifying questions, and discuss trade-offs—the very skills that interviewers use to evaluate problem-solving ability.
We built MockAI to directly address these challenges by creating a scalable, accessible, and intelligent coach that provides affordable, on-demand practice with instant, objective feedback on both technical correctness and the critical communication skills
“You can solve a thousand problems alone in your room, but you don’t know if you’re truly ready until you have to speak.”
“The entire interview process feels like a black box. You go in, you perform, and you get a generic rejection with no feedback. A lot of times, I’m just left guessing about what I did wrong and hoping I get it right next time.”
“The industry has optimized for a very specific skill: solving isolated algorithm problems in silence. But that’s not what the job is. The job is collaboration and clear communication. We are constantly trying to find ways to filter for candidates who have practiced for the real job, not just the test.”
Customer Personas
We identified two primary personas during our initial research, representing key segments of the software engineering job market.


Customer Journey Map

AI Hypotheses
Before committing to a full build, we identified two fundamental AI hypotheses that had to be true for MockAI to succeed.
The Value Hypothesis: Can an AI provide genuinely insightful, accurate, and helpful feedback on a complex technical interview performance?
The Usability Hypothesis: Can we deliver this feedback in a seamless, low-latency, synchronous conversation that feels real?
If we provide job seekers with a synchronous, conversational AI agent that simulates a realistic technical interview, and if that AI can provide instant, actionable feedback on both their technical correctness and their communication skills with over 85% perceived helpfulness, then users will feel more confident and prepared for their real interviews.
This will lead to a high user retention rate and strong word-of-mouth growth. This value can be captured through a freemium model where a premium subscription unlocks unlimited practice and advanced, personalized coaching features, generating a sustainable revenue stream.

Product Roadmap

User Stories & Acceptance Criteria
User-Facing Features
1. Guided Onboarding
User Story: As a first-time user, I want to understand what the AI mock interview will include before I start, so that I feel prepared and know what to expect.
Acceptance Criteria:
The system shall display a 3-step walkthrough (introduction → interview process → feedback format) before the user's first session begins.
The system shall provide a "Skip" option on all walkthrough steps.
The system shall track whether a user has completed the walkthrough and automatically hide it for all subsequent sessions.
2. Dynamic Conversational Flow
User Story: As a user practicing an interview, I want the AI to ask relevant follow-up questions based on my previous answer, so that the session feels like a realistic, dynamic conversation.
Acceptance Criteria:
The system's AI model shall analyze each user answer and determine if a follow-up question is warranted.
If triggered, the system shall generate a maximum of 2 follow-up questions per main interview question.
The generated follow-up question shall reference at least one key concept from the user’s preceding response.
3. Actionable, Structured Feedback
User Story: As a user completing a mock interview, I want to receive feedback that clearly analyzed what went well and what did not, so that I know exactly what to work on.
Acceptance Criteria:
The system shall generate feedback organized into 4 distinct, labeled categories: Communication, Problem Solving, Algorithm Reasoning, and Coding.
Each category section shall contain at least one specific example derived from the user’s response.
The system shall provide a final summary section that gives a detailed analysis of the user’s overall performance and recommends a concrete next step.
Internal & System Requirements
4. Feedback Quality Tracking
User Story: As a product manager, I want to track whether users find the AI feedback helpful, so that I can quantitatively measure the impact of model and prompt improvements.
Acceptance Criteria:
The system shall display a feedback rating UI at the end of each mock interview session.
The rating UI shall allow the user to provide a score (e.g., 1-5 stars) for four distinct categories: Realism, Ease of Use, Feedback Helpfulness, and Overall Satisfaction.
The system shall record each rating event with the required metadata: user_id, chat_id, model_version, and timestamp.The system shall store all rating data in the analytics database.
5. User Engagement Funnel
User Story: As a product manager, I want to measure the full interview completion funnel, so that I can identify and address user drop-off points.
Acceptance Criteria:
The system shall log a session_start event when a user begins the first question of an interview.
The system shall log a session_complete event when a user receives feedback for the final question.
Both events shall include the metadata: user_id, chat_id, model_version, and session_duration_seconds.
The system shall calculate the completion rate as (#session_complete ÷ #session_start) * 100 in the analytics dashboard.
6. System Responsiveness
User Story: As a user, I want the AI to respond quickly after I finish speaking, so that the interview feels realistic and engaging.
Acceptance Criteria:
The system shall begin streaming the AI's text response within 1.0 second after the user input is fully processed.
The system shall deliver the full response output within 3.0 seconds for standard answers.
If the end-to-end latency exceeds 3.0 seconds, the system shall display a "AI thinking…" animation until the full response is ready.
Risks
Product Risk
Risk: The AI's feedback may not be perceived as accurate or helpful, eroding user trust.
Mitigation: A robust automated evaluation harness, a human-in-the-loop review process, and a prominent user feedback mechanism.
Business Risk
Risk: The market for interview prep tools is competitive. A new entrant must have a clear, defensible differentiator
Mitigation: Focus on the superior quality and personalization of our AI feedback, powered by our unique data flywheel and RAG architecture.
Technical Risk
Risk: The complexity of the real-time conversational engine could lead to high latency and a poor user experience.
Mitigation: A staged rollout, starting with a synchronous MVP with limited, curated questions sets to validate the feedback engine before investing heavily in large-scale model training.
KPIs for MockAI
Technical KPIs
Scalability: The system shall handle a 10x increase in concurrent user sessions over 6 months with less than a 5% increase in average response latency.
Accuracy:
Speech-to-Text: Maintain a Word Error Rate (WER) of less than 12% on user transcripts.
AI Feedback: The AI's evaluation (hire/no-hire) shall achieve an agreement rate of >85% with our expert human labelers on a golden test set.
System Uptime: Maintain 99.9% uptime for all user-facing services to ensure the platform is always available for practice.
AI Response Latency: The system shall deliver AI feedback under 1.0 second to maintain a real-time conversational feel.
Reliability: The rate of session failures due to system errors shall be less than 0.1% of all started sessions.
Database Response Time: Maintain an average response time of under 200ms for all primary database queries during peak usage.
Business & Product KPIs
North Star Metric:
Total number of mock interview sessions completed per week. This metric captures the core value delivered to our users. Every completed session represents a moment of practice, feedback, and learning.
Counter Metric:
Average "Feedback Helpfulness" Score. We track the user-reported helpfulness score (1-5 stars) on all completed interview sessions. This ensures that as we drive up the volume of completed questions, we are not sacrificing the quality and perceived value of the feedback, which is our core differentiator.
Product Health Metrics:
Weekly Active Users (WAU): Define "Active" as a user who completes at least one interview session in a 7-day period.
Session Completion Rate: The percentage of users who start an interview session and complete all of its questions. This is our key funnel metric.
D7 Repeat Usage Rate: The percentage of new users who return to complete a second interview session within 7 days of their first session. This measures the product's "stickiness."
Free-to-Paid Conversion Rate: The percentage of free users who upgrade to a premium subscription each month. This measures the effectiveness of our monetization strategy.
Monthly Recurring Revenue (MRR): The predictable revenue from premium subscribers, indicating our business's health.
Customer Lifetime Value (LTV): The total revenue we can expect from a single customer account. This informs our user acquisition and long-term strategy.
User-Reported Confidence Score: A quarterly survey asking users to rate how much more prepared they feel for real interviews after using MockAI. This directly measures our impact on the user's primary goal.
AI Input & Output
Our system is designed to process complex, multi-modal user input and generate structured, actionable feedback.

AI Input
User Audio & Video (Unstructured): Real-time audio and video stream captured from the user's microphone and webcam during the interview.
User Code (Structured): The final code solution typed into the editor by the user.
User Context (Structured): The specific LeetCode problem being attempted, and for premium users, the job description or target company.
Retrieved RAG Context (System Input): Relevant text chunks from our Vector Database (e.g., coding style guides, alternative solutions, company values).

AI Output
AI Dialogue (Text & Audio): The interviewer's questions, hints, and follow-ups, generated as text and converted to a high-quality audio stream via our TTS service. This audio is played over a pre-rendered, looping video of the interviewer avatar to create an immersive experience.
Structured Feedback Report: A detailed analysis broken down into four categories: Communication, Problem Solving, Algorithm Reasoning, and Coding.
Code Correctness Score: A binary pass/fail result from the Judge0 engine.
Personalized Improvement Tip: A single, actionable "Next Step" recommendation for the user.
AI Models Overview
MockAI's intelligence is powered by a sophisticated, multi-layered AI stack designed to handle the complete interview lifecycle, from understanding the user to generating expert-level feedback.
| Model / Service | Purpose | Model Characteristics |
|---|---|---|
| Speech-to-Text (Deepgram) | To accurately transcribe the user's spoken answers into text in real-time. | A state-of-the-art deep learning model optimized for high accuracy and low latency on streaming audio, crucial for a conversational experience. |
| Core LLM (Fine-Tuned GPT-4o) | To act as the conversational AI interviewer, generate relevant follow-up questions, and provide nuanced feedback on the user's performance. | A powerful, multi-modal LLM, fine-tuned on our proprietary dataset of 10k+ Problem & Solution pairs to specialize in the patterns, language, and evaluation criteria of technical interviews. |
| RAG Embedding Model (OpenAI text-embedding-3) | To convert our external and internal knowledge bases (style guides, user transcripts) into vector representations for semantic search. | A leading model designed to capture the semantic meaning of text, enabling our RAG system to retrieve highly relevant context for any given interview scenario. |
| Code Execution Engine (Judge0) | To deterministically verify the correctness of a user's code against a suite of hidden test cases. | An open-source, secure sandboxing engine that can compile and run code in multiple languages, providing objective, pass/fail results. |

Data Pipeline
Our data pipeline is the flywheel that continuously improves our AI's intelligence. It consists of two main loops: a real-time RAG pipeline for on-the-fly context, and an offline fine-tuning pipeline for long-term skill improvement.
1. The Real-Time RAG Pipeline
This pipeline executes in milliseconds every time a user interacts with the AI, ensuring the feedback is contextually relevant.
Step 1: User Input & Contextual Query
User audio is captured and transcribed to text in real-time via Deepgram.
The transcript, user code, and all interaction metadata are logged and stored in our Postgres DB.
The Flask Backend sends this transcript and the interview context to LangChain.
Step 2: Retrieval & Augmentation
LangChain queries our Vector Database to retrieve relevant, pre-indexed context (e.g., code style best practices, explanations of alternative algorithms)
This context is added to the prompt to make the AI's response smarter and more relevant.
Step 3: Generation & Correctness Check
The final, augmented prompt is sent to our fine-tuned GPT-4o model on Azure AI to generate a response.
Simultaneously, the user's code is sent to the Judge0 engine for correctness validation.
2. The Offline Fine-Tuning Pipeline
This pipeline runs continuously in the background to make our core AI model smarter with every interview conducted.
Step 1: Data Logging
The complete data for every session (the transcript, user code, AI feedback, and the user's final rating) is logged and stored as a structured record in our Postgres DB.
Step 2: Labeling & Curation
This raw data is fed into our AI Improvement system.
Our LLM Eval and expert Human Labelers review these sessions, correcting errors and creating "golden standard" examples of perfect feedback. This turns raw data into a high-quality, curated training set.
Step 3: Fine-Tuning
Periodically, this new, curated dataset is used to further fine-tune our core GPT-4o model on Azure AI.
This process teaches the model to better understand user patterns and improves its core skills, providing a powerful defense against data drift and ensuring our AI's intelligence is always evolving.
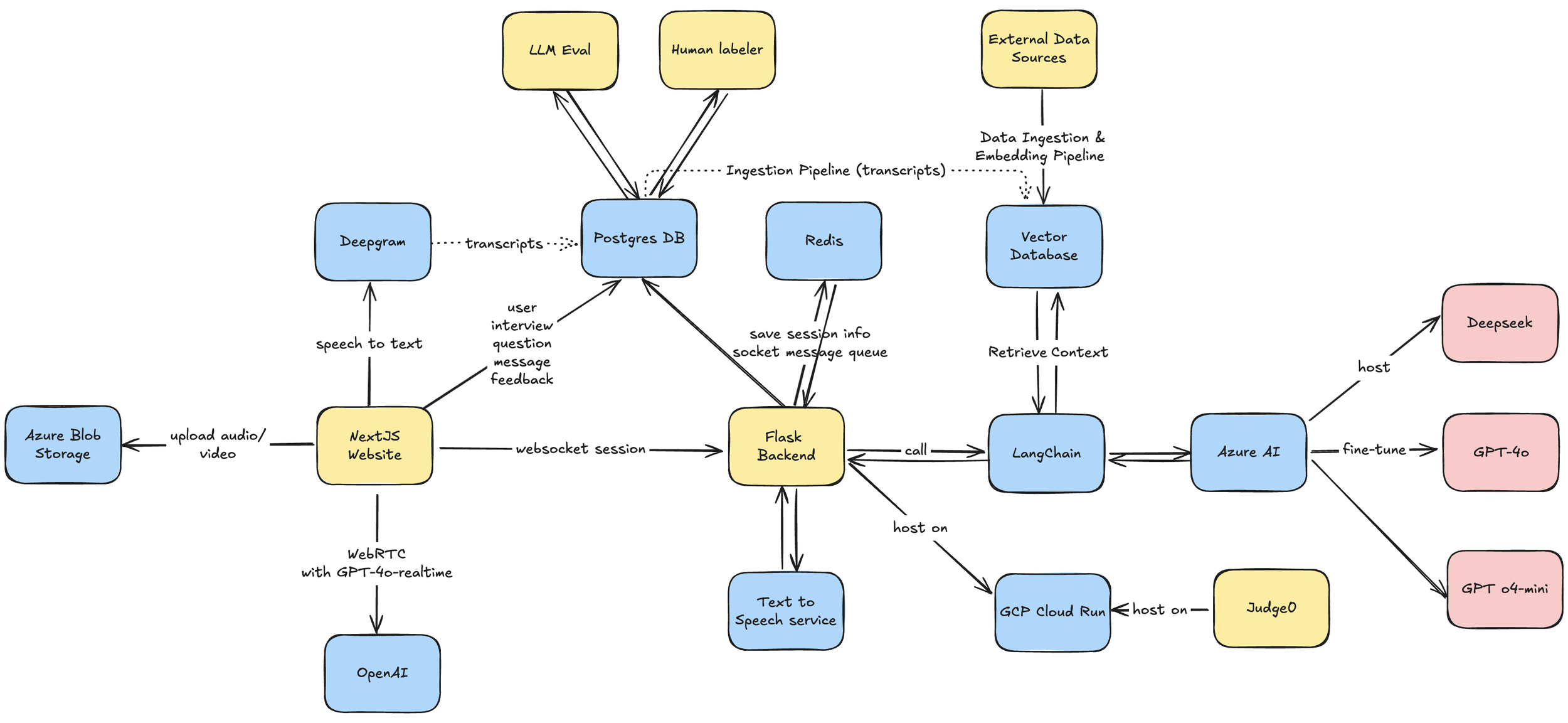
System Architecture
The MockAI platform is built on a modern, scalable, and modular cloud architecture designed for real-time AI applications.
The system consists of a Next.js frontend, a central Flask backend orchestrator, and a suite of specialized AI and data services. Key components include Deepgram for speech-to-text, a Postgres database for primary data, Redis for caching, a Vector Database for our RAG pipeline, and fine-tuned LLMs hosted on Azure AI.
AI Product Scalability
MockAI's architecture is designed for scalability, ensuring our AI can deliver a high-quality, real-time experience as our user base grows.
Our strategy is built on three pillars:
Continuous Model Improvement & Adaptation
A key challenge for any AI product is data drift. Our core defense is our continuous Supervised Fine-Tuning (SFT) pipeline, which adapts our model to evolving user patterns and interview trends.
The next evolution is to incorporate Reinforcement Learning from Human Feedback (RLHF) to scale the quality and nuance of our AI's judgment. By training a reward model on expert preferences, we will align our AI with the principles of great coaching, especially for ambiguous domains like System Design interviews.
Scalable Knowledge Base
Our RAG architecture allows us to scale the AI's factual knowledge independently of the core model. We can add new company data or best practices to our Vector Database without having to retrain the LLM, making our system incredibly agile and up-to-date.
Mitigating AI Risks
To reduce the risk of inaccurate feedback ("hallucinations"), we use RAG to ground the AI's responses in factual data. Furthermore, we use the deterministic Judge0 engine for all code correctness checks. This ensures that this core part of our evaluation is 100% reliable and not subject to the probabilistic nature of LLMs, which is a key component of our product's trustworthiness.
Business Model
MockAI operates on a freemium, product-led growth (PLG) model designed to maximize user acquisition while creating a clear path to sustainable revenue. Our strategy is to allow every user to experience the core "magic" of the product for free, and then offer a powerful premium tier for our most dedicated users.
Free Tier
The Free tier is the top of our funnel, designed to remove all barriers to entry and prove our value proposition to a wide audience. It provides a generous but limited offering that is perfect for a user like "Alex" to get started.
Core Offering: One 45-minute mock interview per week with the Basic AI, including a detailed interview report.
Strategic Goal: Drive user acquisition, gather valuable data to improve our AI, and build a large pool of engaged users who understand the product's value, creating a natural upgrade path.
Premium Tier
The Premium tier is designed for our most motivated users, like "Jessica," who are in an active job search and need to maximize the efficiency and depth of their preparation. It's a comprehensive suite of tools that turns MockAI into an indispensable coaching platform.
Core Offering:
Volume & Depth: Unlimited mock interviews and full access to our 3000+ question library.
Deeper Intelligence: Access to our most advanced, fine-tuned AI models and the latest real interview questions.
Personalization: Features like "Target Company Practice" and "Growth Tracking" to tailor the experience to the user's specific goals.
Pricing Strategy: We offer flexible subscription plans to align with a user's specific interview timeline and commitment level.
Monthly ($40/month): Maximum flexibility for users with an immediate interview.
Quarterly ($30/month): A balanced option for users in an active, multi-month job search.
Yearly ($24/month): The best value for students and professionals committed to continuous, long-term skill development.
This tiered model allows us to serve the entire market, from casual learners to serious job seekers, creating a sustainable business that grows with our users' success.
MVP (Minimum Viable Product)
Our go-to-market strategy was centered on a two-stage MVP process to validate our idea with the least amount of risk and investment.
The No-Code MVP: A Landing Page to Gauge Interest
Goal: To test the core value proposition before writing a single line of code.
Execution: We launched a simple landing page describing MockAI as "Your Personal AI Interview Coach." It had one call-to-action: "Request Early Access."
Result: The high sign-up rate (over 1,000 in the first few weeks) gave us the initial conviction we needed to proceed with building the product.
The Functional MVP: A Closed-Alpha Experience
Goal: To prove that a real-time, synchronous conversation with an AI could feel realistic and engaging enough to be a viable product for real users.
Scope: A focused, closed-alpha experience opened to only 50 target users. The product was intentionally minimal: it had a fixed library of 20 basic algorithm questions, guided candidates through a standard interview flow, saved their session data (dialog + code), and produced a simple feedback summary.
Result: The alpha test was a huge success. We proved that the core synchronous experience was not only technically feasible but felt "surprisingly realistic" to our first users. This validated our riskiest assumption and gave us the precise, data-driven mandate to focus the entire V1.0 roadmap on enhancing the intelligence of the feedback engine.
Product Launch
As the founding Product Manager, I led the official v1.0 product launch, taking MockAI from a closed-alpha of under 50 users to a public platform.
User Growth & Result
By executing a product-led growth strategy and rapidly iterating based on user feedback, I helped scaled our user base to over 7K registered users in the first 3 months post-launch.